
Documentation > Deployment > OLAP JVM Snapshots
This page describes how to use new experimental JVM Snapshot to execute analytical (OLAP) queries in H-Store.
Overview
JVM Snapshots allows for H-Store to execute analytical queries without interfering with the normal OLTP workload. When executing analytical queries directly on the H-Store, it will block all the other transactions and execute the distributed transaction, which usually takes longer time than transactional queries. This has a significant impact on the performance of the whole system. With JVM Snapshots, the H-Store site will send the analytical transaction to the JVM Snapshot. In this way, it avoid the expensive concurrency control because the snapshot database has only one distributed transaction.
The trickier part is how to create the snapshot. Since H-Store is a main memory database, we can use fork() to create a consistent virtual memory snapshot, which contains all the information the system need to execute OLAP query.
Fork has a nice property that is called Copy-on-Write. When the process is forked, the operating system does not need to make actual physical memory copies. Instead, virtual memory pages in both processes may refer to the same pages of physical memory until one of them writes to such a page: then it is copied. And this process is controlled implicitly by the operating system.
Thus the creation of snapshots is lightweight and fast. But the downside is that it may hurt the performance of write operations, because after creating the snapshot, each writing operation will trigger a page allocation which is an overhead that cannot be neglected in main memory DBMS.
Implementation Details
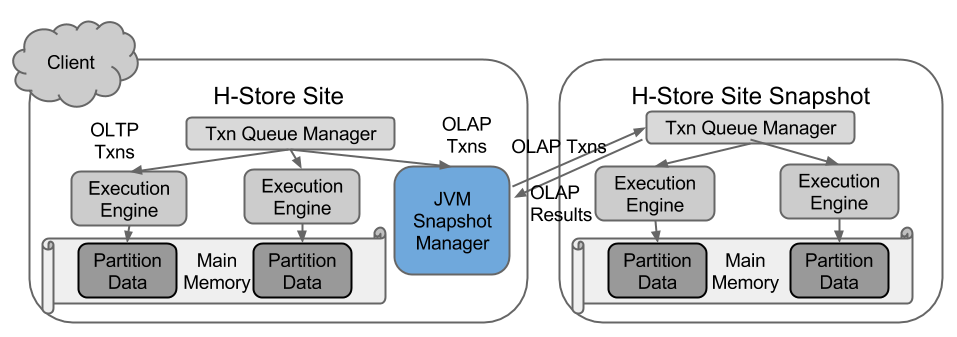
Most of the work is done by the JVM Snapshot Manager that runs in a separate thread in the H-Store site. The Manager is in charge of creating, refreshing snapshots, communicating with snapshots and queuing OLAP queries.
When H-Store receives an OLAP query, it will parse and compile the SQL statement and generate a transaction object. Then it will put the transaction object in the queue of JVM Snapshot Manager. In the Manager main loop, it will check the queue and retrieve the OLAP transaction. Then it will check whether the current snapshot is available. If not, it will fork a new snapshot and wait for the initialization of the snapshot. Then it will send the OLAP transaction to the snapshot and wait for response.
In the snapshot process, it will first respawn partition execution engine threads and some other essential utility threads. After that it will set up socket connection with the parent process and wait for OLAP transaction or shutdown command. In this way only one query is executed in the snapshot at one time because the queuing happens in the JVM Snapshot Manager, which makes the logic of the snapshot much easier.
The communication between snapshot and the manager is socket connection. There are three types of messages: OLAP transaction request, OLAP transaction response, and shutdown.
Here the snapshot should be recreated after a certain amount of time to make sure the data in the snapshot will not be too stale. However, creating a new snapshot may introduce overhead and affect the OLTP performance, so here is a tradeoff between data staleness and performance. This is controlled by site.jvmsnapshot_interval.
Evaluation
While H-Store is executing TPC-C or read-only TPC-C workload, we manually invoke OLAP queries towards the system to measure the influence caused by OLAP queries.
The OLAP query is drawn from another OLAP benchmark TPC-H. The query requires a full table scan on ORDER_LINE, which is the busiest table in the TPC-C benchmark:
SELECT ol_number, SUM(ol_quantity), SUM(ol_amount), AVG(ol_quantity), AVG(ol_amount), COUNT(*) FROM order_line WHERE ol_delivery_d > '2007-01-02 00:00:00.000000' GROUP BY ol_number ORDER BY ol_number |
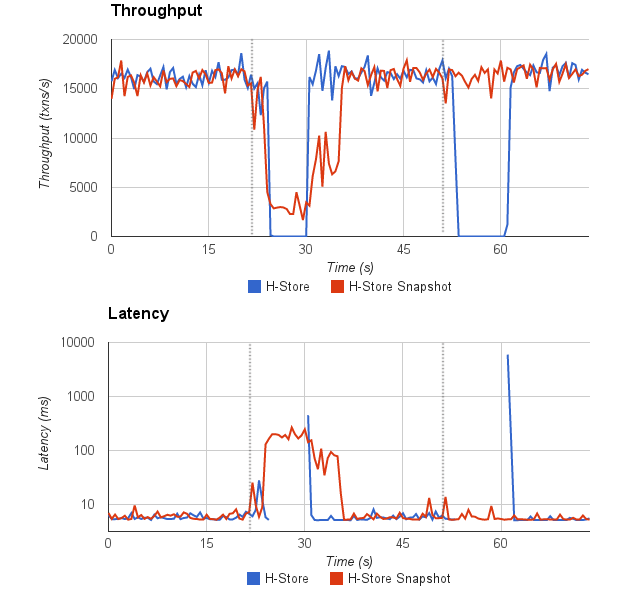
The graph show how throughput and latency evolves with time for OLTP queries in TPC-C benchmark. The vertical dotted line indicates when the OLAP query is invoked. We run two OLAP queries. and only the first query need to fork a new snapshot.
In the original H-Store, we can see a dramatic drop of throughput while the OLAP is being executed. Actually the throughput reaches zero for several seconds. This result matches our expectation because the OLAP query is a distributed transaction and it needs to block all the data to do a full table scan.
In the snapshot one, we can still see a large drop in the first query. That is because TPCC is a write intensive benchmark, after the snapshot is created, every operation would invoke a page allocation, which hurt the throughput performance. But after all pages are copied, it will not affect the performance, as we can see in the second query. The latency graph shows the same pattern as the throughput.
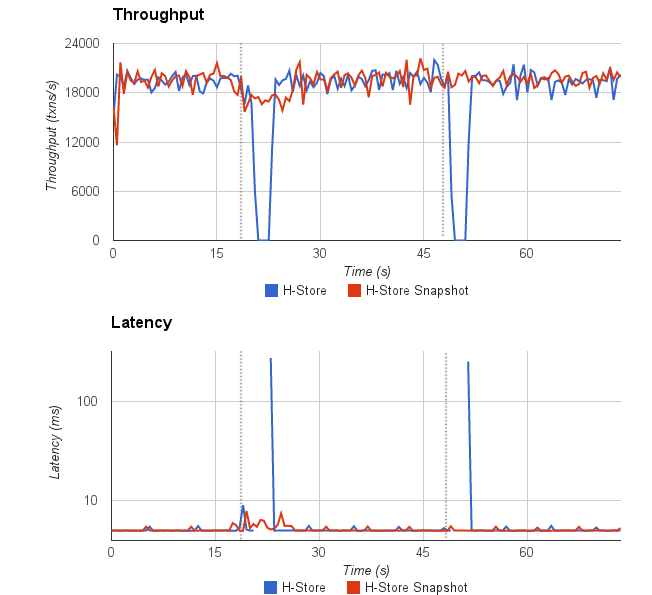
The graph below show how throughput and latency evolves with time for OLTP queries in read-only TPC-C benchmark, which means we remove all write transactions in TPC-C. We can see that the influence is reduced a lot in the first query. This can confirm our conclusion that the performance drop in the original TPC-C benchmark is caused by write operations. There is still a small drop, that is because of the Java Garbage collection, variable assignment, and variable allocation.
Future Work
The current implementation is highly experimental and can’t be put into production. The main reason for this is that fork() is not designed for multi-thread programs. It only copies the CPU state of the thread that called it and all the other threads are lost. Since our system runs inside a Java Virtual Machine, this means all Garbage Collection, Resource Management threads in JVM are lost, which makes the system unstable. Also this may introduce concurrency issues because we lose the concurrency state in other threads.
Future directions include:
- Implement distributed snapshots, which enables us to run multi-machine transactions on the snapshots.
- Solve the consistency issue in snapshot. We may need to add a fake transaction to fork the snapshot to make sure that no other transactions are running while creating the snapshot.
- Put Execution Engine (C++) in a separate process and only fork EE process to avoid JVM snapshot limitations.
- Try timestamp versioning method, which means that the system stores multiple timestamp versioned data for each tuple and we run OLAP queries on data with a specific timestamp.